OpenAI Evals
AIOpen SourceFreeOpen-source framework and registry for creating, running, and comparing evaluations of large language models and LLM systems.
OpenAI Evals
Open-source framework and registry for creating, running, and comparing evaluations of large language models and LLM systems.
About OpenAI Evals
OpenAI Evals is an open-source framework and benchmark registry for evaluating large language models and systems built with them. It provides a library, examples, and a registry of community and official evals that you can run locally or via the OpenAI platform, plus tools to author custom and private evals that reflect your workflows. Evals supports automated graders, rubric-based scoring, human-in-the-loop grading, dataset integration, and continuous evaluation to track model performance and regressions. Contributions to the public registry are MIT-licensed and contributors must ensure they have rights to any uploaded data; running evals typically incurs inference costs through the OpenAI API.
Screenshots
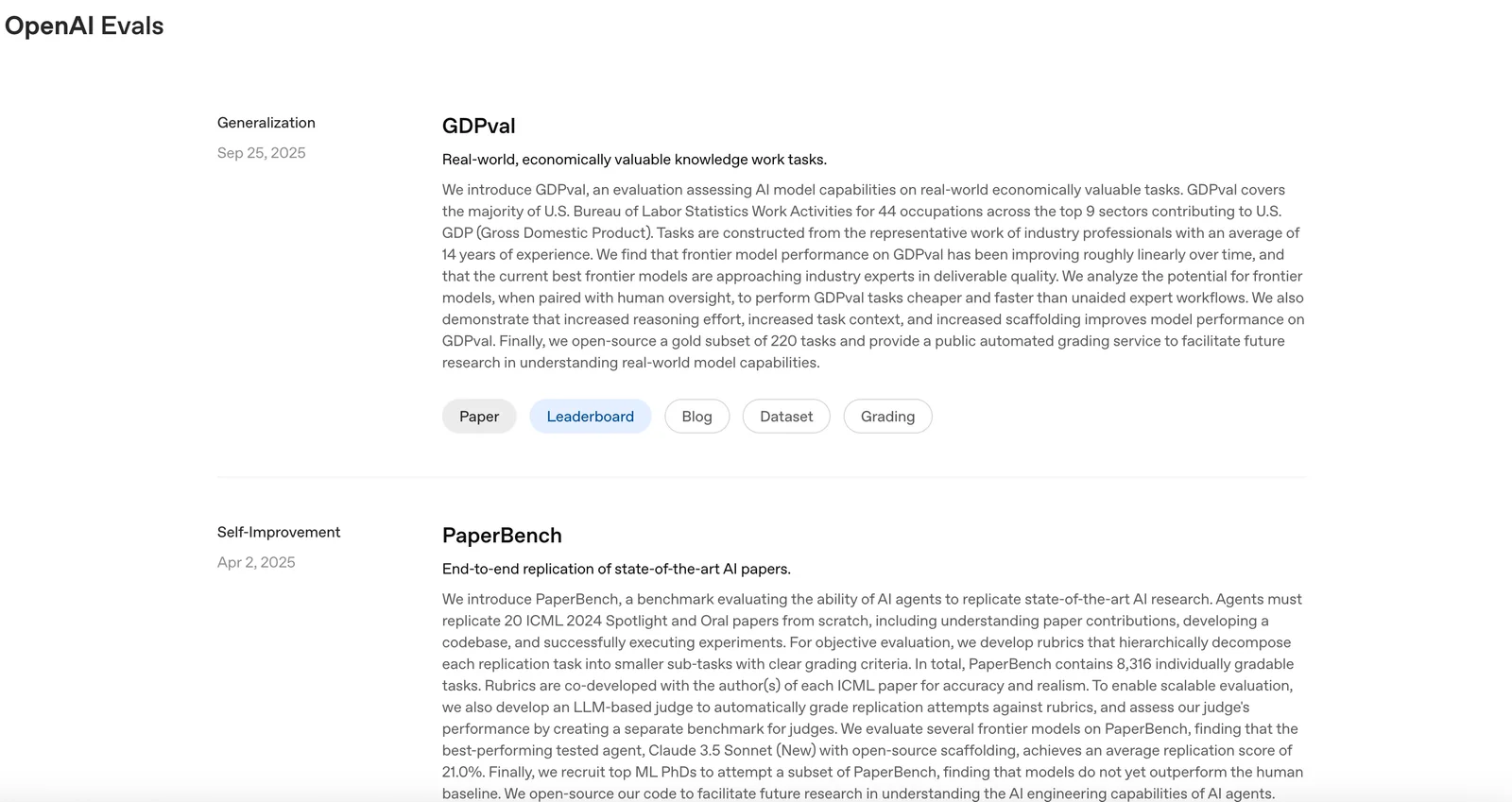
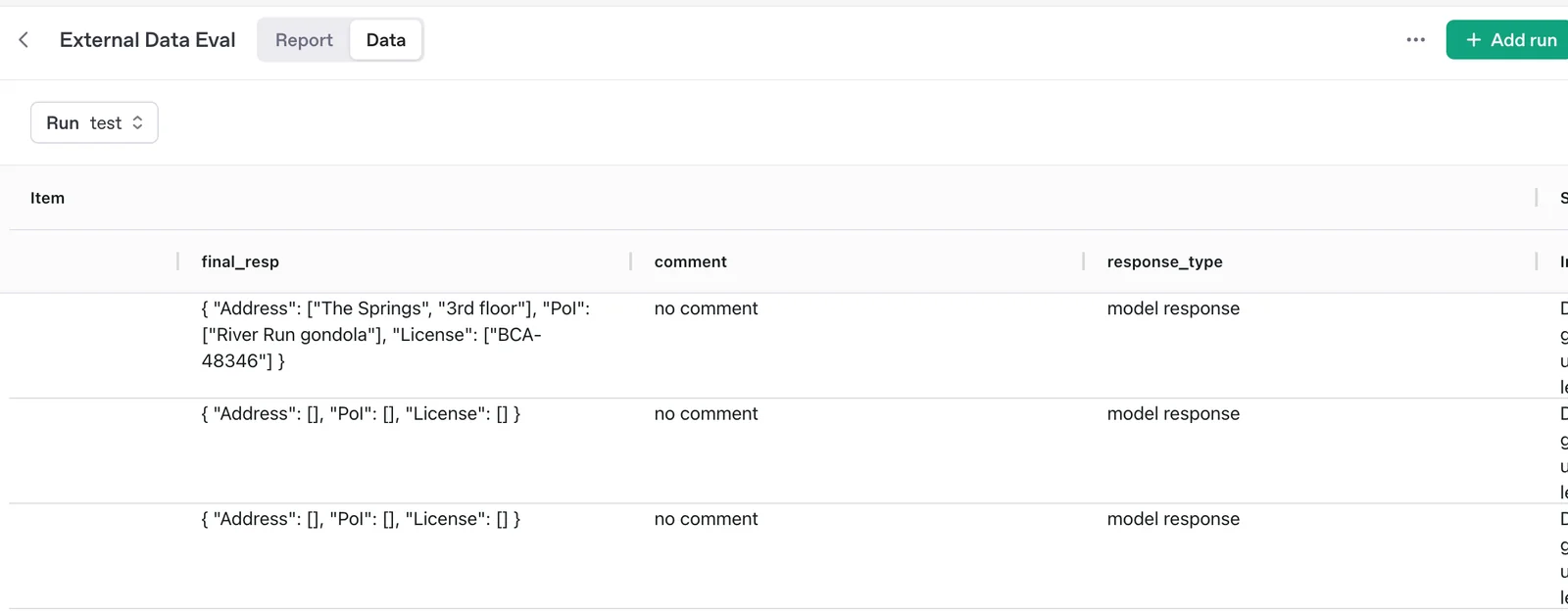
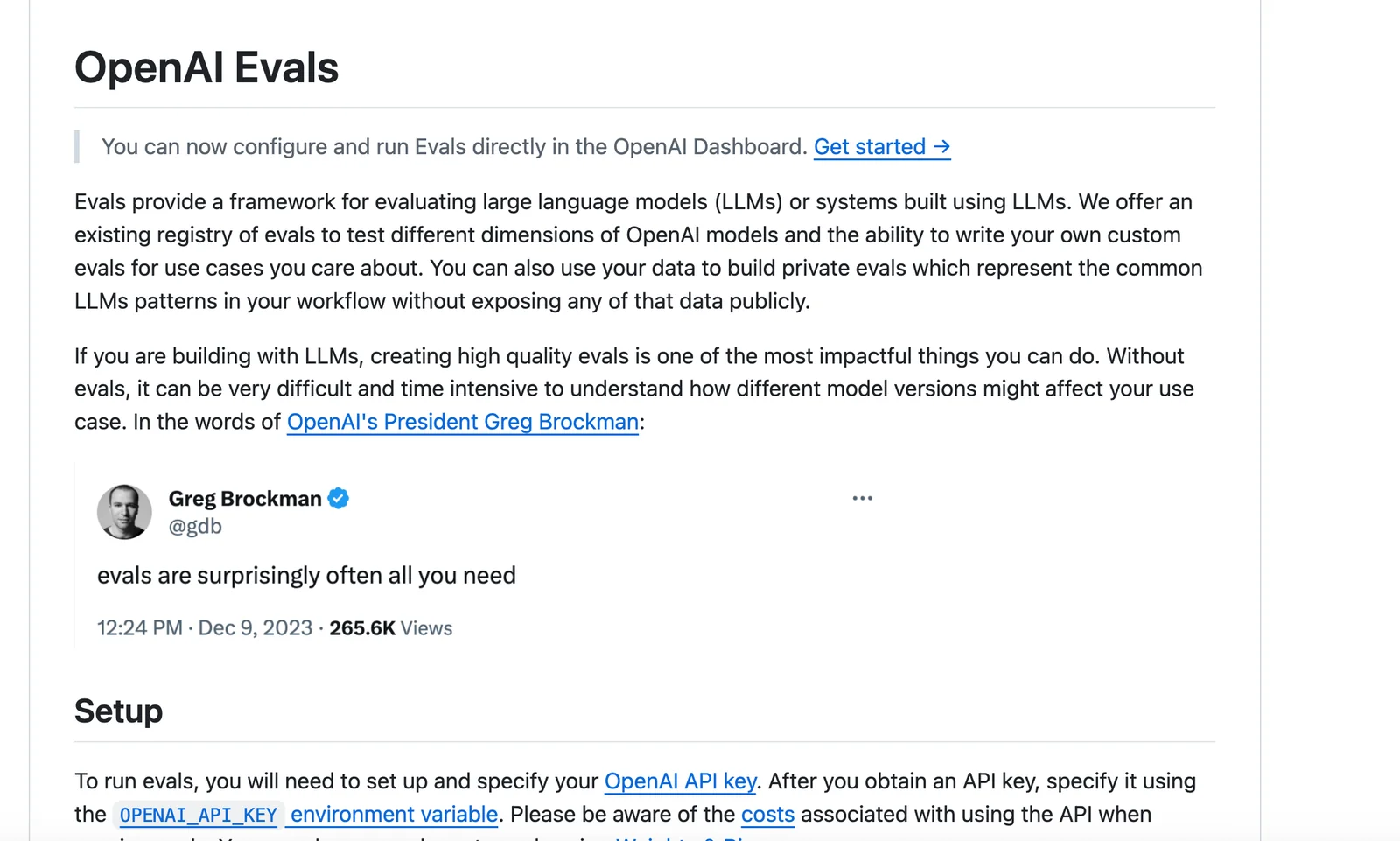
Key Features
Use Cases

Explore more AI Ai Tools tools
Browse all Ai Tools tools →Browse by use case: Automation & Productivity
Compare OpenAI Evals: vs OpenArt Director · vs Voicebox · vs World Monitor · vs Alai 2.0