
Avatar Forcing
AIOpen SourceFreeReal-time framework that generates interactive head avatars from audio and motion using diffusion forcing for low-latency, expressive reactions.
Avatar Forcing
Real-time framework that generates interactive head avatars from audio and motion using diffusion forcing for low-latency, expressive reactions.
About Avatar Forcing
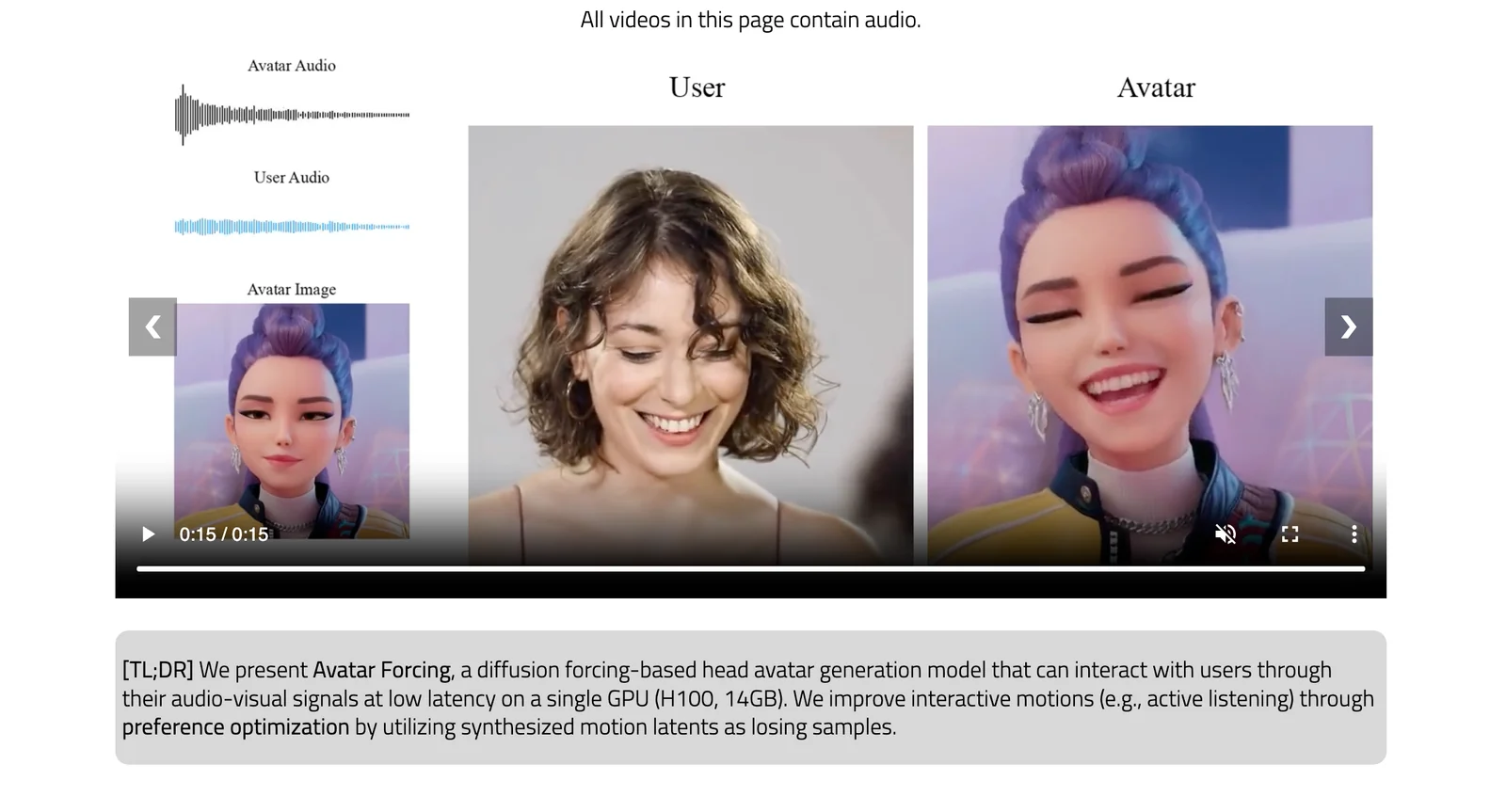
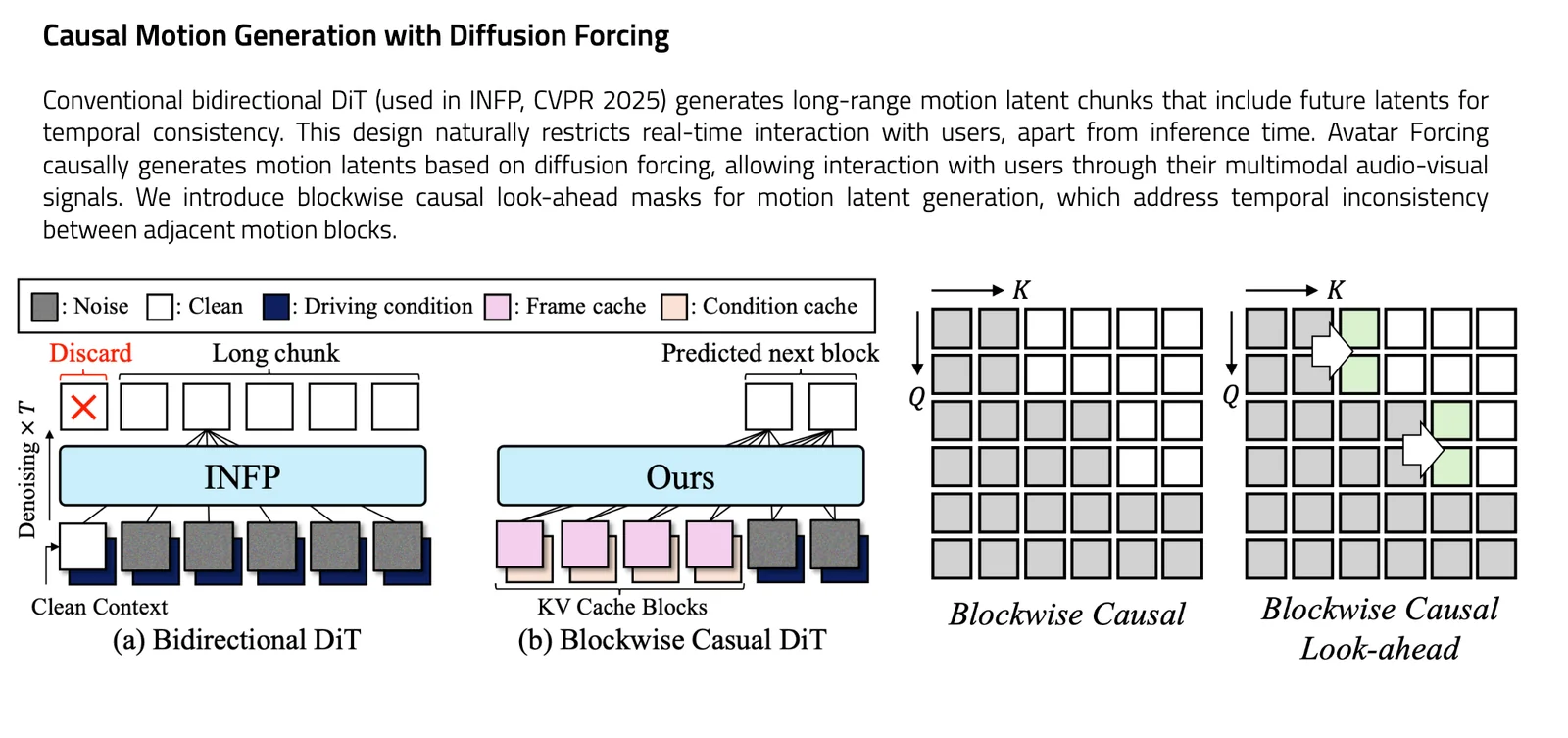
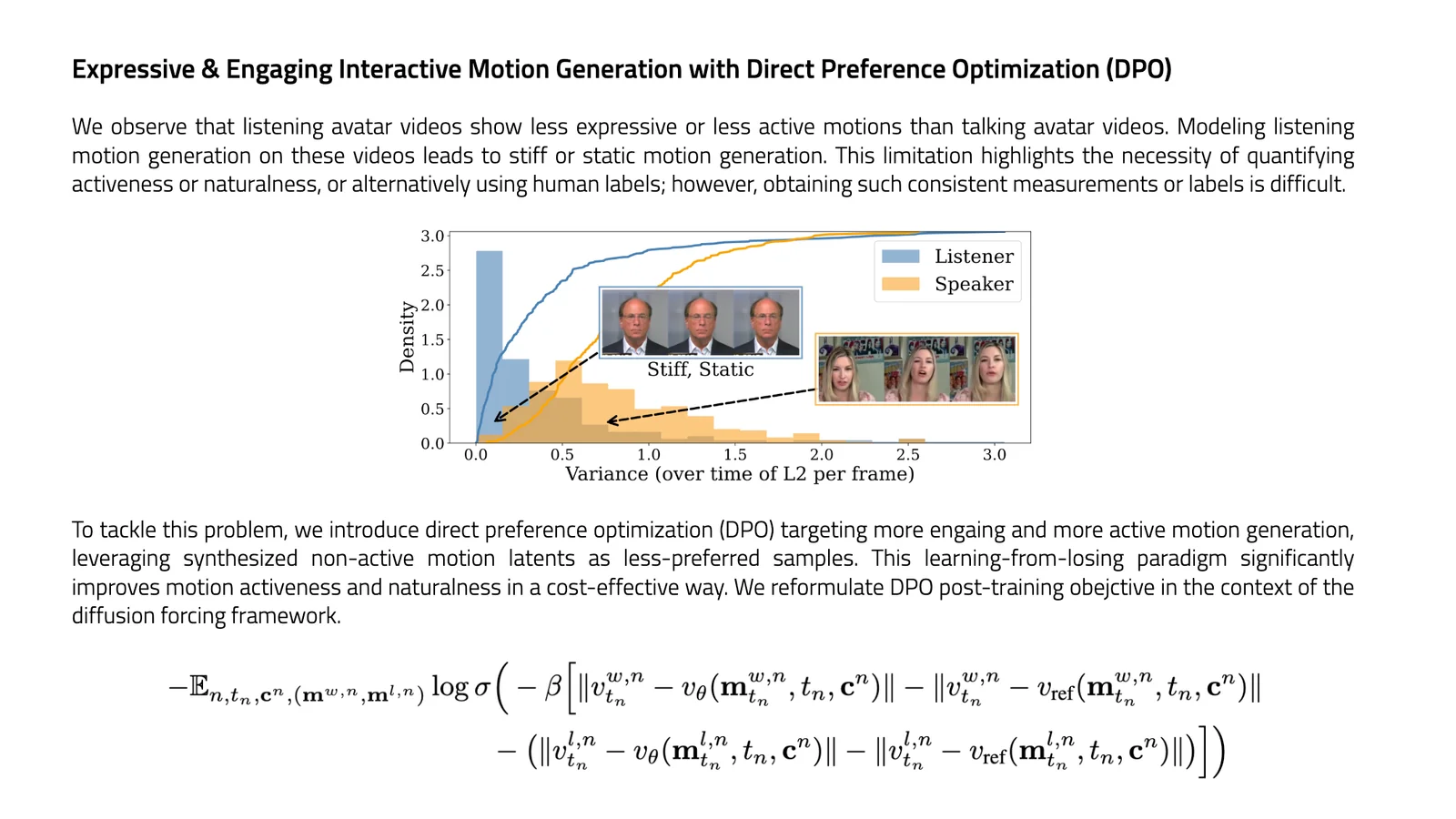
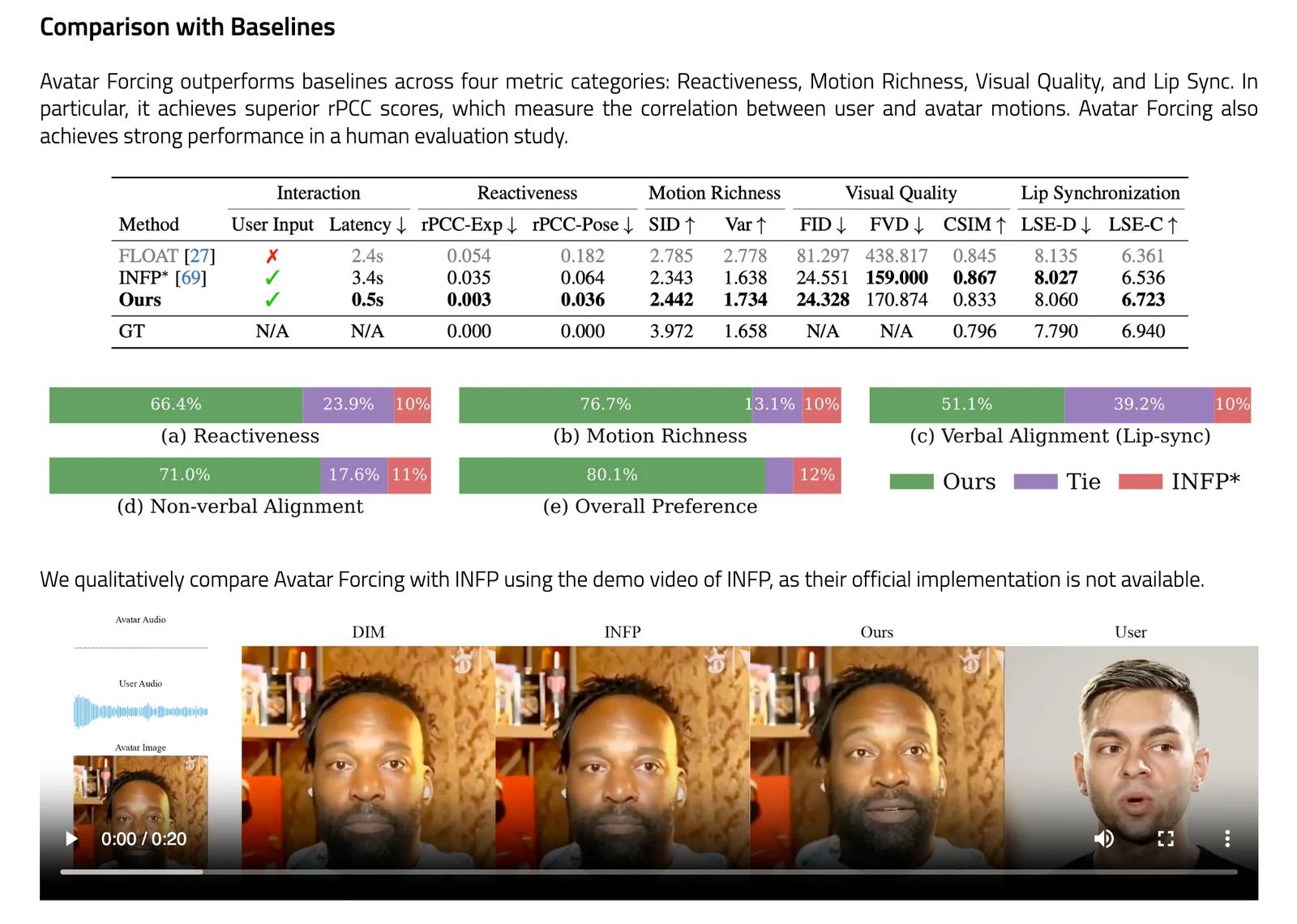
Avatar Forcing is a research framework for real-time, interactive head-avatar generation that conditions on multimodal user inputs (audio and motion) to produce expressive, reactive facial and head motion. It introduces Motion Latent Diffusion Forcing to enable causal, low-latency generation (reported ~500 ms) and a direct preference optimization method that uses synthetic "losing" samples (created by dropping user conditions) to learn expressive reactions without additional labeled data. The method is presented in an arXiv preprint and an official PyTorch implementation project page/repository; experiments report a 6.8x speedup over baselines and user preference rates over 80% versus baseline methods.
Screenshots

Key Features
Use Cases



Explore more AI Ai Models tools
Browse all Ai Models tools →Browse by use case: Voice & Audio
- Laguna by Poolside
- Arena AI: The Official AI Ranking & LLM Leaderboard
- PromptLayer
- PHBench
- Mercury Edit 2
- OpenRouter Model Fusion
Compare Avatar Forcing: vs Laguna by Poolside · vs Arena AI: The Official AI Ranking & LLM Leaderboard · vs PromptLayer · vs PHBench